03
Oct
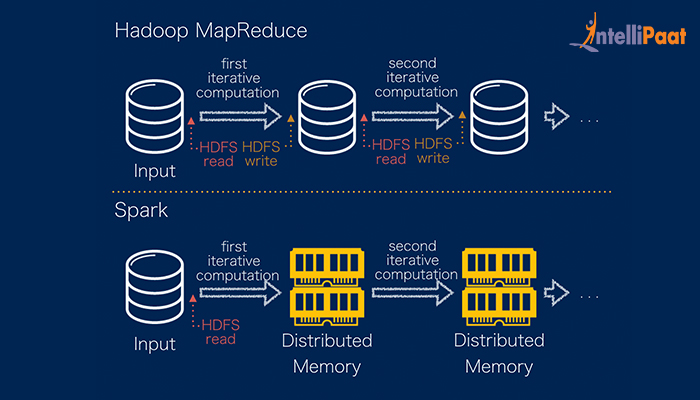
The reason is that Apache Spark processes data in-memory RAM while Hadoop MapReduce has to persist data back to the disk after every Map or Reduce action. In many cases also these run faster on Spark than on MapReduce.
Why spark is faster than mapreduce. Why is Apache Spark faster than MapReduce. Data processing requires computer resource like the memory storage etc. In Apache Spark the data needed is loaded into the memory as Resilient Distributed Dataset RDD and processed in parallel by performing various transformation and action on it.
In some cases the output RDD from one task is used as input to. Various reasons of Spark being Faster than MapReduce. Spark uses RAM to storing intermediate data during processing while MapReduce uses Disk to store intermediate data.
In this video I talk about why Apache Sparks in memory processing. Thats why Spark is so much faster than Mapreduce or other analytics frameworks. There are various factor that makes Spark is faster than MapReduce.
It is said that Spark is 100 times faster than Hadoops MapReduce. Here is some of the factors that are making it super fast. Spark is not processing the data in Disk it process the huge amount of data in RAM.
Hence it will cut off the time required to do read write operation in disk. All it supports parallel processing of data that makes it 100 times faster. Processing at high speeds.
The process of Spark execution can be up to 100 times faster due to its inherent ability to exploit the memory rather than using the disk storage. MapReduce has a big drawback since it has to operate with the entire set of data in the Hadoop Distributed File System on the completion of each task which increases the time and cost of processing data. In many cases also these run faster on Spark than on MapReduce.
The primary advantage Spark has here is that it can launch tasks much faster. MapReduce starts a new JVM for each task which can take seconds with loading JARs JITing parsing configuration XML etc. Spark keeps an executor JVM running on each node so launching a task is simply a matter of making an RPC to it and passing a Runnable to a thread pool which takes in the single digits of milliseconds.
Apache Spark is potentially 100 times faster than Hadoop MapReduce. Apache Spark utilizes RAM and isnt tied to Hadoops two-stage paradigm. Apache Spark works well for smaller data sets that can all fit into a servers RAM.
Hadoop is more cost effective processing massive data sets. Apache Spark is now more popular that Hadoop MapReduce. The biggest claim from Spark regarding speed is that it is able to run programs up to 100x faster than Hadoop MapReduce in memory or 10x.
Map reduce is not able to cache in memory data so its not as fast as compared to Spark. Spark caches the in-memory data for further iterations so its very fast as compared to Map Reduce. Map Reduce supports more security projects and features in comparison to Spark.
Spark security is not yet matured as that of Map Reduce. Spark was designed to be faster than MapReduce and by all accounts it is. In some cases Spark can be up to 100 times faster than MapReduce.
Spark uses RAM random access memory to process data and stores intermediate data in-memory which reduces the amount of read and write cycles on the disk. This makes it faster than MapReduce. Spark can launch tasks faster using its executor JVM on each data processing node.
This makes launching a task just a single millisecond rather than seconds. It just needs making an RPC and adding the Runnable to the thread pool. No jar loading XML parsing etc are associated with it.
The key difference between Hadoop MapReduce and Spark. In fact the key difference between Hadoop MapReduce and Spark lies in the approach to processing. Spark can do it in-memory while Hadoop MapReduce has to read from and write to a disk.
As a result the speed of processing differs significantly Spark may be up to 100 times faster. However the volume of data processed. For Spark data is stored in the cache memory and when the final transformation is done action only then it is stored in HDFS.
This saves a lot of time. Spark uses lazy evaluation with the help of DAG Directed Acyclic Graph of consecutive transformations. This reduces data shuffling and the execution is optimized.
Apache Spark is well-known for its speed. It runs 100 times faster in-memory and 10 times faster on disk than Hadoop MapReduce. The reason is that Apache Spark processes data in-memory RAM while Hadoop MapReduce has to persist data back to the disk after every Map or Reduce action.
First of all Spark is not faster than Hadoop. Hadoop is a distributed file system HDFS while Spark is a compute engine running on top of Hadoop or your local file system. Spark however is faster than MapReduce which was the first compute engine created when HDFS was created.
So when Hadoop was created there were only two things. It is a framework that is open-source which is used for writing data into the Hadoop Distributed File System. It is an open-source framework used for faster data processing.
It is having a very slow speed as compared to Apache Spark. It is much faster than MapReduce. It is unable to handle real-time processing.
Hadoop MapReduce is meant for data that does not fit in the memory whereas Apache Spark has a better performance for the data that fits in the memory particularly on dedicated clusters. Hadoop MapReduce can be an economical option because of Hadoop as a service offering HaaS and availability of more personnel. Spark is usually fast as it brings the data in memory so its good for repetitive processing and faster preferred over hive.
In my experience- I prefer hive with mapreduce as processing engine for large data load 100gb and over and will prefer spark for dataset with few gb.
Previous post
Wic whole grain choices waNext post
Why must cells undergo mitosis